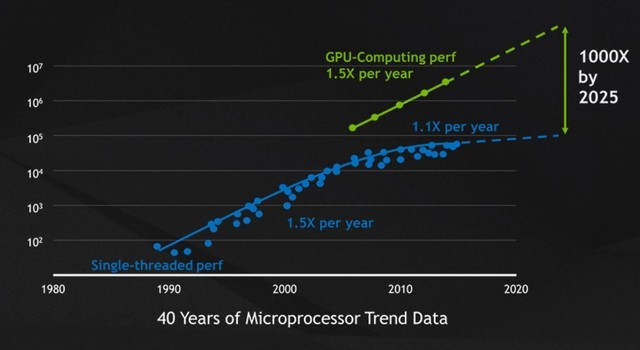
过去30多年,摩尔定律几乎每年都会推动微处理器的性能提升50%,而半导体的物理学限制却让其放慢了脚步。如今,CPU的性能每年只能提升10%左右。事实上,英伟达CEO黄仁勋在每年的GTC上都会提到同一件事——摩尔定律失灵了。也就是说,人们要获得更强的计算力,需要花费更多的成本。与此同时,GPU的崛起速度令人咂舌,看看英伟达近两年的股价就知道了。
微处理器趋势图(图片来自NVIDIA)
随着人工智能、深度学习等技术的兴起与成熟,起初为图像渲染而生的GPU找到了新的用武之地,以GPU驱动的计算环境随处可见,从HPC到AI训练。站在数字世界、高性能计算、人工智能的交叉口,GPU悄然成为了计算机的大脑。将性能从10倍提升至100倍,GPU的加速能力远超以X86架构构建的CPU系统,将时间压缩至分钟级别,功耗也相对较低。
2006年,借助CUDA(Compute Unified Device Architecture,通用计算架构)和Tesla GPU平台,英伟达将通用型计算带入了GPU并行处理时代,这也为其在HPC领域的应用奠定了基础。作为并行处理器,GPU擅长处理大量相似的数据,可以将任务分解为数百或数千块同时处理,而传统CPU则是为串行任务所设计,在X86架构下进行多核编程是很困难的,并且从单核到四核、再到16核有时会导致边际性能增益。同时,内存带宽也会成为进一步提高性能的瓶颈。
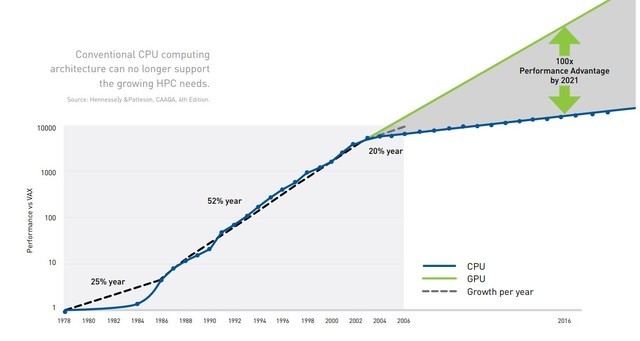
传统CPU计算架构难以支撑快速成长的HPC(图片来自NVIDIA)
与以往的通用算法相比,深度学习对计算性能的要求则到了另一个量级上。尽管在GPU中运行并行核心时处理的应用数量相同,但在系统中单个内核的使用效率却更高。此外,经过重写的并行函数在应用程序关键部分运行时,在GPU上跑的速度更快。
更重要的是,英伟达在利用GPU构建训练环境时还考虑到了生态的重要性,这也是一直以来困扰人工智能发展的难题。首先,英伟达的NVIDIA GPU Cloud上线了AWS、阿里云等云平台,触及到了更多云平台上的开发者,预集成的高性能AI容器包括TensorFlow、PyTorch、MXNet等主流DL框架,降低了开发门槛、确保了多平台的兼容性。
其次,英伟达也与研究机构、大学院校,以及向Facebook、YouTube这样的科技巨头合作,部署GPU服务器的数据中心。同时,还为全球数千家创业公司推出了Inception项目,除了提供技术和营销的支持,还会帮助这些公司在进入不同国家或地区的市场时,寻找潜在的投资机会。
可以说,英伟达之于GPU领域的成功除了归功于Tesla加速器、NVIDIA DGX、NVIDIA HGX-2这些专属的工作站或云服务器平台,更依托于构建了完整的产业链通路,让新技术和产品有的放矢,从而形成了自己的生态圈,这也是英特尔难以去打破的。
本文属于原创文章,如若转载,请注明来源:人工智能芯片产业面面观 谁将成就最强大脑//net.zol.com.cn/690/6902344.html