微软Azure云平台近日宣布针对3项数据服务展开升级,包括推出正式版数据湖存储服务Data Lake Storage Gen2,数据完全托管服务Data Explorer,以及预览版的混合数据整合服务Data Factory,来满足用户对于高性价比+安全的云端数据分析服务需求。
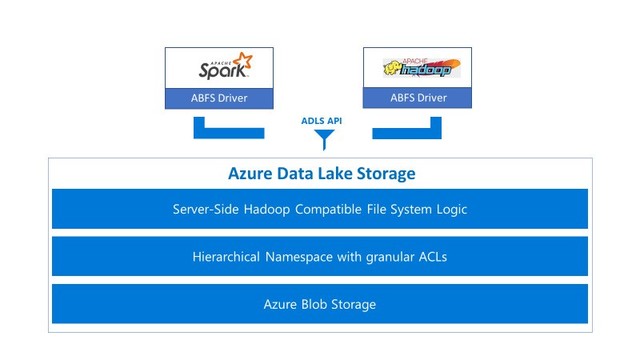
据悉,数据湖存储服务Data Lake Storage Gen2适用于大型数据分析,其结合了Azure非结构化存储服务Blob Storage的可扩展性、安全模型和丰富的功能于一身,再加上为分析所设计的高效能文件系统,能与Hadoop分布式文件系统兼容,让用户选择云端数据湖服务时,无需在成本和效能中取舍。
微软指出,自家数据湖存储服务其中一项主要目标,即是要与Apache生态系统兼容。为了做到这点,微软开发Azure Blob文件系统驱动程序,该驱动程序正式成为Apache Hadoop和Spark的一部分,并且附于许多Hadoop的商业版本中。
为了进一步提升Data Lake Storage Gen2的分析能力,微软用分层命名空间,收集文件集合并整理成分层目录和巢状子目录,此种命名空间对巨量数据分析架构相当重要,由于Hive或是Spark等工具经常将输出写入暂时位置,并在操作结束时重新命名该位置,若没有分层命名空间,重新命名所花费的时间通常会比分析流程本身更长。因此,分层命名空间可用较少的计算资源,来加速任务执行并降低成本。
而Data Explorer是一个快速且具有高扩展性的完全托管数据分析服务,能够针对大量的流数据进行即时分析。在不需要修改数据结构的情况下,一秒内能够查询10亿笔记录。此外,该服务能与微软云端其他服务相连,像是Data Lake Storage、SQL Data Warehouse、Power BI。为了提升速度和简化操作,Data Explorer由两个分别的服务组成:Engine服务和数据管理服务,这两项服务都在Azure中,以计算节点的集群形式部署。
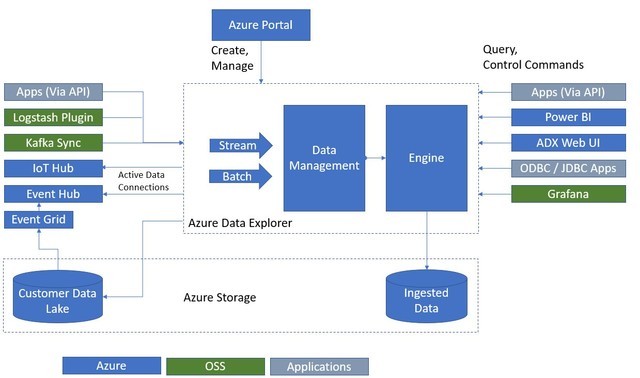
数据管理服务负责消化多种不同型态的原始数据,并且管理数据清理、执行失败和反压机制等任务,还能通过自动索引和压缩机制快速处理数据。而Engine服务则是负责处理输入的原始数据和用户的查询,通过自动扩展和数据分割来达到高效能的目标。

此外,Azure此次升级还推出了混合数据整合服务Data Factory预览版,Data Factory服务是用来将数据移动和转换工作自动化的服务,内建超过80个与结构化、半结构化和非结构化数据源的连接器。除此之外,该服务还提供数据工作流程可视化工具Mapping Data Flow,提供用户在设计、建置和管理数据转换的过程有可视化的体验,不需要学习Spark或是对分布式基础架构有深入的了解。
本文属于原创文章,如若转载,请注明来源:Azure升级3大服务 拔高云端数据分析能力//net.zol.com.cn/709/7091657.html



















































