2023年10月11日-13日,在中国移动全球合作伙伴大会举办期间,中兴通讯“星云研发大模型”亮相,旨在辅助开发人员进行需求分析、产品设计、编程、测试、版本部署等,全流程助力研发提效。经第三方HumanEval评估,“星云研发大模型”位于编码类模型第一梯队,编码语言种类多样性能力和中文编码能力达到业内领先水平。
兴算力智生长,中兴通讯“星云研发大模型”亮相
直击痛点,“星云研发大模型”助力研发提效
对程序员多种编程语言的高能力要求、长时间的开发周期,是现代软件敏捷开发中常见的两个研发痛点。为解决上述痛点,中兴通讯推出“星云研发大模型”,辅助开发人员进行需求分析、产品设计、编程、测试、版本部署以及产品文档编写,为开发者提供一站式、智能化的研发体验,让每个软件开发者都有自己的开发助手。
其次,“星云研发大模型”保障研发全流程的安全可控,包括支持白名单机制有效控制使用范围;代码特征值识别有效识别敏感代码片段;敏感词识别机制可实时监测并拦截敏感内容;完备的后台审计机制可完整回溯安全事件等。
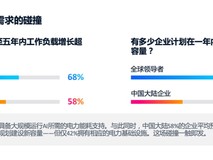
2023年4月,“星云研发大模型”使用启动,截至目前,日活人数达1.2万人, 代码采纳率达40%~45%,编码提效30%, 整体研发提效10%。
关键技术突破,“星云研发大模型”达业内领先
星云研发大模型具有“三全两一”的特性,“三全”即中兴通讯全自研编码模型;全流程助力研发提效;支持与合作伙伴的全方位合作;“两一”即“星云研发大模型”位于编码类模型第一梯队;助力整体研发提效10%
中兴通讯将大量高质量的领域数据、Know-How知识积累、中兴通讯多年沉淀的数十万篇通信领域技术文档和1000亿token的无线/核心网/云代码语料等注入大模型,进行增量预训练,使用并行训练框架。其次,使用高质量精调数据进行模型精调,满足辅助编程场景应用,提升研发效率。
中兴通讯自研部署方案,使用动态batch策略、PagedAttention技术,结合无损模型量化,吞吐量大幅提升,单GPU(A800)达到1500tokens/s,仅使用4张GPU卡(A800)可满足超千人使用需求。对比业界常规的部署方案,(NVIDIA FasterTransformer和Huggingface Transformer),单GPU吞吐量分别提升10+倍和20+倍;结合int4量化技术,在模型精度不下降情况下,模型大小和显存使用量均下降一半,能有效降低部署成本。
“星云研发大模型”携手伙伴,加速演进
大规模预训练语言模型正以惊人的速度演进,在自然语言处理、计算机视觉、语音识别等领域取得了显著进展,通用人工智能的前景正日益清晰。面向未来,中兴通讯“星云研发大模型”将从模型、算子、语料、算法、平台等全产品维度,与行业伙伴全方位合作,助力数智化转型,携手共赴智能山海,开创智算生长新篇章。
本文属于原创文章,如若转载,请注明来源:兴算力智生长,中兴通讯“星云研发大模型”亮相https://net.zol.com.cn/836/8364755.html